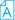
Дата:16/09/16
 Исследователи из Лаборатории информатики и искусственного интеллекта (CSAIL) при Массачусетском технологическом институте представили новый язык программирования под названием Milk, ориентированный на работу с разрозненными фрагментами данных в больших массивах.
Исследователи из Лаборатории информатики и искусственного интеллекта (CSAIL) при Массачусетском технологическом институте представили новый язык программирования под названием Milk, ориентированный на работу с разрозненными фрагментами данных в больших массивах.
Считается, что современные вычислительные системы не оптимизированы для работы с разрозненными данными. Процесс извлечения информации из оперативной памяти не достаточно быстрый. По этой причине процессоры оснащаются собственной памятью, называемой кэшем. Для того чтобы сократить количество обращений к ОЗУ, процессор считывает память блоками и находит необходимые данные в этих блоках уже в собственном кэше.
Такой подход зарекомендовал себя, когда дело касается вычислительной системы с локальной памятью. Однако если речь идет о сетевой базе данных большого объема, например, хранящей 2 млн фрагментов данных, в которой необходимо найти 20 определенных фрагментов, указанный подход неэффективен. Именно чтобы решить эту проблему и был создан новый язык.
В ходе тестов, проведенных исследователями, выяснилось, что применение нового языка позволяет в четыре раза ускорить работу с разрозненными данными в больших массивах по сравнению с существующими языками, сообщает Cnews.ru.









Создан эффективный язык программирования для больших данных
Исследователи из Лаборатории информатики и искусственного интеллекта (CSAIL) при Массачусетском технологическом институте представили новый язык программирования под названием Milk, ориентированный на работу с разрозненными фрагментами данных в больших массивах.Считается, что современные вычислительные системы не оптимизированы для работы с разрозненными данными. Процесс извлечения информации из оперативной памяти не достаточно быстрый. По этой причине процессоры оснащаются собственной памятью, называемой кэшем. Для того чтобы сократить количество обращений к ОЗУ, процессор считывает память блоками и находит необходимые данные в этих блоках уже в собственном кэше.
Такой подход зарекомендовал себя, когда дело касается вычислительной системы с локальной памятью. Однако если речь идет о сетевой базе данных большого объема, например, хранящей 2 млн фрагментов данных, в которой необходимо найти 20 определенных фрагментов, указанный подход неэффективен. Именно чтобы решить эту проблему и был создан новый язык.
В ходе тестов, проведенных исследователями, выяснилось, что применение нового языка позволяет в четыре раза ускорить работу с разрозненными данными в больших массивах по сравнению с существующими языками, сообщает Cnews.ru.
Просмотры: 389
При использовании ссылка на ictnews.az обязательна
Похожие новости
- Возросший интерес к iPad снизил поставки персональных компьютеров
- Число сотовых абонентов в Китае превысило 900 миллионов
- Российский рынок связи может заработать дополнительно $3 млрд
- Папа Римский станет редактором на новом новостном портале
- Лютфи Заде поблагодарил Президента Ильхама Алиева
- Британское правительство берет на работу эксперта по открытому коду
- Apple приближается к юридической победе в споре с тайваньской HTC
- 22 июля - День национальной прессы Азербайджана
- Xalq Bank начал выпуск Visa Internet Card
- В США забастовали 45 тыс. сотрудников оператора Verizon
- Известный ИТ-бизнесмен погиб в автокатастрофе
- Министерство транспорта Азербайджана планирует применить единую систему оплаты в общественном транспорте
- С начала года к азербайджанской образовательной сети подключены около 100 школ
- ГКВИ объявил набор IT консультантов для регистрации недвижимости и кадастра
- В Азербайджане продлены лицензии двух телерадиоструктур