Date:26/10/17
 Devices like Amazon’s Echo and Google Home can usually deal with requests from a lone person, but like us they struggle in situations such as a noisy cocktail party, where several people are speaking at once.
Devices like Amazon’s Echo and Google Home can usually deal with requests from a lone person, but like us they struggle in situations such as a noisy cocktail party, where several people are speaking at once.
Now an AI that is able to separate the voices of multiple speakers in real time promises to give automatic speech recognition a big boost, and could soon find its way into an elevator near you.
The technology, developed by researchers at the Mitsubishi Electric Research Laboratory in Cambridge, Massachusetts, was demonstrated in public for the first time at this month’s Combined Exhibition of Advanced Technologies show in Tokyo.
It uses a machine learning technique the team calls “deep clustering” to identifies unique features in the “voiceprint” of multiple speakers. It then groups the distinct features from each speaker’s voice together, allowing it to disentangle multiple voices and then reconstruct what each person was saying. “It was trained using 100 English speakers, but it can separate voices even if a speaker is Japanese,” says Niels Meinke, a spokesperson for Mitsubishi Electric.
Meinke says the system can separate and reconstruct the speech of two people speaking into a single microphone with up to 90 per cent accuracy. If there are three speakers the accuracy dips, but is still up to 80 per cent. In both cases, this was with speakers the system had never encountered before.
Conventional approaches to this problem – such as using two microphones to replicate the position of a listener’s ears – have only managed 51 per cent accuracy.
In overcoming the “cocktail party effect” that has dogged AI research for decades, the new technology could help smart assistants in homes and cars work better. It could also improve automatic speech transcription, and be used to help law enforcement agencies reconstruct recordings of conversations that had been muddied by music, for example.
In preliminary tests the system was able to separate the voices of up to five people at once. “The system could be used to separate speech in a range of products including lifts, air-conditioning units and household products,” says Meinke.
Indeed, Mitsubishi is now in the process of building its voice recognition technology into lifts and air-conditioners, among other products.







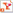


AI has learned how to pick a single voice out of a crowd
Devices like Amazon’s Echo and Google Home can usually deal with requests from a lone person, but like us they struggle in situations such as a noisy cocktail party, where several people are speaking at once.Now an AI that is able to separate the voices of multiple speakers in real time promises to give automatic speech recognition a big boost, and could soon find its way into an elevator near you.
The technology, developed by researchers at the Mitsubishi Electric Research Laboratory in Cambridge, Massachusetts, was demonstrated in public for the first time at this month’s Combined Exhibition of Advanced Technologies show in Tokyo.
It uses a machine learning technique the team calls “deep clustering” to identifies unique features in the “voiceprint” of multiple speakers. It then groups the distinct features from each speaker’s voice together, allowing it to disentangle multiple voices and then reconstruct what each person was saying. “It was trained using 100 English speakers, but it can separate voices even if a speaker is Japanese,” says Niels Meinke, a spokesperson for Mitsubishi Electric.
Meinke says the system can separate and reconstruct the speech of two people speaking into a single microphone with up to 90 per cent accuracy. If there are three speakers the accuracy dips, but is still up to 80 per cent. In both cases, this was with speakers the system had never encountered before.
Conventional approaches to this problem – such as using two microphones to replicate the position of a listener’s ears – have only managed 51 per cent accuracy.
In overcoming the “cocktail party effect” that has dogged AI research for decades, the new technology could help smart assistants in homes and cars work better. It could also improve automatic speech transcription, and be used to help law enforcement agencies reconstruct recordings of conversations that had been muddied by music, for example.
In preliminary tests the system was able to separate the voices of up to five people at once. “The system could be used to separate speech in a range of products including lifts, air-conditioning units and household products,” says Meinke.
Indeed, Mitsubishi is now in the process of building its voice recognition technology into lifts and air-conditioners, among other products.
Views: 690
©ictnews.az. All rights reserved.
Similar news
- The mobile sector continues its lead
- Facebook counted 600 million active users
- Cell phone testing laboratory is planned to be built in Azerbaijan
- Tablets and riders outfitted quickly with 3G/4G modems
- The number of digital TV channels will double to 24 units
- Tax proposal in China gets massive online feedback
- Malaysia to implement biometric system at all entry points
- Korea to build Green Technology Centre
- Cisco Poised to Help China Keep an Eye on Its Citizens
- 3G speed in Azerbaijan is higher than in UK
- Government of Canada Announces Investment in Green Innovation for Canada
- Electric cars in Azerbaijan
- Dominican Republic Govt Issues Cashless Benefits
- Spain raises €1.65bn from spectrum auction
- Camden Council boosts mobile security